
ここでは『対応のあるt検定』の解析方法を紹介します。
EZRの検定名は『対応ある2群間の平均値の比較 (paired t検定)』となります。
検定を使う前に使うための条件を満たしているか確認しましょう。
- 対応のあるデータ
- 連続変数
- 正規分布している
- 2群間の比較
順番に表で確認すると対象の検定が使えるかが判断できます。
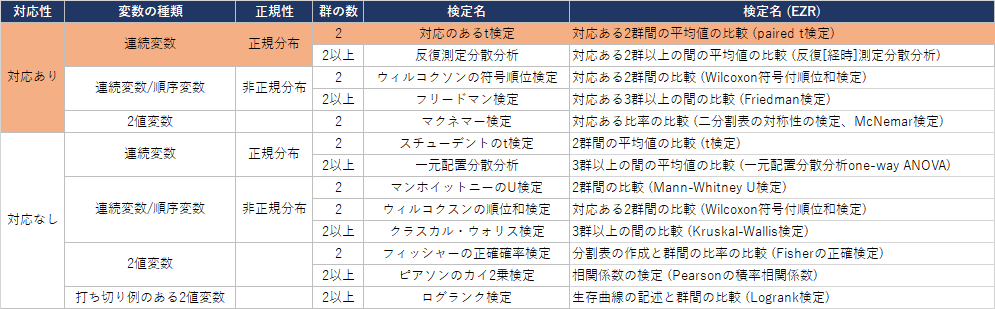
『対応のある』、『対応のない』の見分けかた
ここで『対応のある』、『対応のない』という言葉で困惑する方が多いので違いを理解しておきましょう。単純に同じ対象のデータか、違う対象のデータかで分類されています。
| 対応のある | 対応のない | |
| 同じ対象で測定したデータ |
具体的には
『対応のある』の例:同じ5人の朝の血圧と夜の血圧を比較する
『対応のない』の例:例:A町の5人の血圧とB町の5人の血圧を比較する
データのインポート
ここではサンプルデータを用意して、クリップボードからEZRにデータをインポートします。
他のインポート方法は以下のリンクを参考にしてください。

サンプルに用意したデータは筋トレ前(pre)と筋トレ後(post)の筋力を比較するデータです。
対応のあるt検定 (paired t検定) ではデータは比較したいデータを横に並べます。左の列に筋トレ前(pre)、右の列に筋トレ後(post)を置いています。
データのコピー
インポートしたい (コピーしたい) 範囲を選んで「右クリック→コピー (Ctrl+C))」をします。
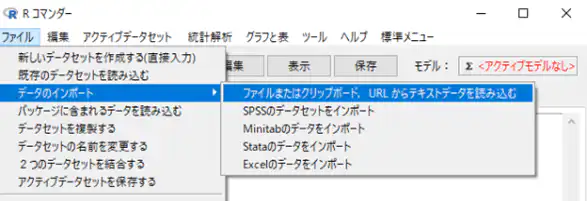
EZRにインポート
Rコマンダーで「ファイル」→「データのインポート」→「ファイルまたはクリップボード, URLからデータを読み込む」を選択します。
データセット名は自由に入力してください。「Dataset」のままでも問題ありません。
「クリップボード」、「タブ」を選択して「OK」をクリックします。
すでに何らかのデータがインポートされている場合は上書きしてよいか確認が表示されます。
問題なければ「Yes」をクリックします。
これでデータのインポートは完了です。
対応のあるt検定 (paired t検定) の手順
Rコマンダーで「統計解析」→「連続変数の解析」→「対応のある2群間の平均の比較(paired t検定)」の順に選択します。
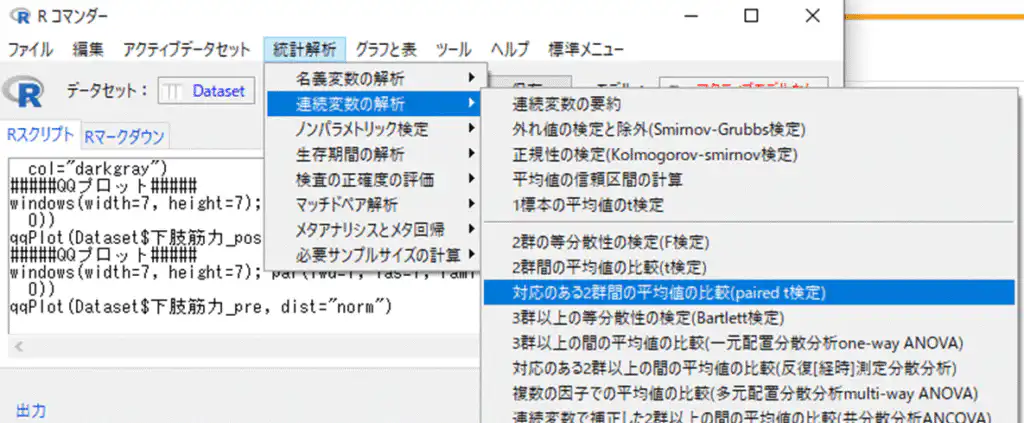
第1の変数に「pre」、第2の変数に「post」を選択して「OK」を押します。
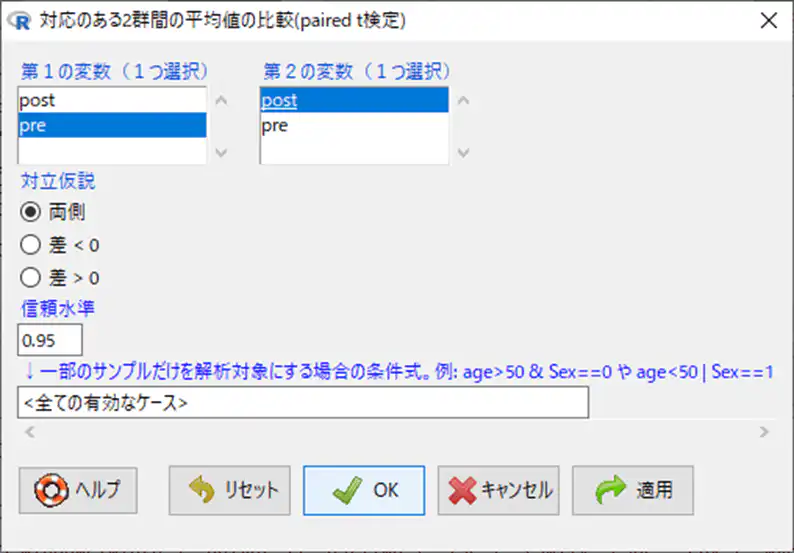
Rコマンダーに結果が表示されます。

今回は筋トレ前(pre)の平均が22.94、筋トレ後(post)の平均が27.84で、P値は0.012でした。
P<0.05で「有意差あり」と判断できます。したがって、今回のサンプルデータでは「筋トレ前(pre)と比べて筋トレ後(post)は有意に筋力の値が上昇した。」という結果となりました。
最後に
今回は「対応のあるt検定 (paired t検定)」の手順の紹介でした。トレーニング効果などを見るときにはよく使う方法なので覚えておくと便利だと思います。
ただし、実際には筋トレの負荷量や期間などが対象によって異なるとデータに影響が出てしまうため注意が必要です。具体的にはトレーニング負荷が10RMの人と、30RMでは筋力向上の効果が異なりますし、筋トレ期間も1日と2か月では効果が異なります。対応としては多変量解析を行ったり、出来るだけ筋トレ方法を統一するなど、ばらつきを減らす必要があります。
